Gelegentlich benötigt man bei der Entwicklung einer Datenbank eindeutige IDs, die aber dennoch editierbar bleiben müssen. So kann es sinnvoll sein, bei der Erzeugung eines neuen Datensatzes sich vom System eine neue eindeutige ID vorschlagen zu lassen, diese aber aufgrund von außerhalb des Systems liegenden Randbedingungen auch ändern zu können (z.B. als Fremdschlüssel). Das ist eine gefährliche Sache und bedarf einiger Umsicht. Dieser Artikel beschäftigt sich mit dieser Umsicht und ein paar Kniffen bei der Entwicklung eines FileMaker-Systems.
Für im System interne Schlüssel empfiehlt sich zumindest bei Bedarf nach Synchronisation von mehreren Instanzen eines Systems (z.B. mobile Geräte mit einer Server-Instanz) die Verwendung von alphanumerischen Schlüsseln über die Status-Funktion Hole ( UUID ), die dann auch nicht editierbar sein sollten. Gerne hat man aber auch Schlüssel, die dem Benutzer präsentiert werden sollen und die numerisch sein sollen oder eine numerische Komponente haben.
Hier bietet es sich an, bei der Erzeugung eines Datensatzes die ID automatisch als fortlaufende Nummer generieren zu lassen. Dann ist es aber keine gute Idee, die editierbar zu machen (Änderungen durch den Benutzer zuzulassen). Die Eindeutigkeit kann man zwar über den Reiter „Überprüfung“ sicherstellen, doch per Hand erzeugte Lücken in der Folge der IDs erzeugen Probleme.
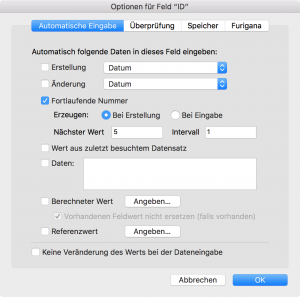 Im rechts dargestellten Beispiel vergibt das System bei der Erzeugung des nächsten Datensatzes automatisch die ID = 5. Wenn der Benutzer diese ID aufgrund von anderen Randbedingungen z.B. auf 7 ändert, mag das zwar weiterhin eindeutig sein, bringt aber bei der weiteren Erzeugung von Datensätzen Probleme mit sich: der nächste Datensatz bekommt die (eindeutige) ID = 6 und dann kommt es zum Konflikt: Bei der Erzeugung des nächsten Datensatzes versucht das System die schon vorhandene ID = 7 zu wählen und der Benutzer bekommt Fehlermeldungen angezeigt, die er gar nicht mehr versteht. Das kann man zwar mit Triggern und dem Scriptschritt „Nächste fortlaufende Nummer setzen“ heilen, aber das ist hässlich und zerstört den Vorteil der automatischen ID-Generierung. Dann ist es besser, auf die automatische Generierung komplett zu verzichten und die neue ID selbst zu erzeugen.
Im rechts dargestellten Beispiel vergibt das System bei der Erzeugung des nächsten Datensatzes automatisch die ID = 5. Wenn der Benutzer diese ID aufgrund von anderen Randbedingungen z.B. auf 7 ändert, mag das zwar weiterhin eindeutig sein, bringt aber bei der weiteren Erzeugung von Datensätzen Probleme mit sich: der nächste Datensatz bekommt die (eindeutige) ID = 6 und dann kommt es zum Konflikt: Bei der Erzeugung des nächsten Datensatzes versucht das System die schon vorhandene ID = 7 zu wählen und der Benutzer bekommt Fehlermeldungen angezeigt, die er gar nicht mehr versteht. Das kann man zwar mit Triggern und dem Scriptschritt „Nächste fortlaufende Nummer setzen“ heilen, aber das ist hässlich und zerstört den Vorteil der automatischen ID-Generierung. Dann ist es besser, auf die automatische Generierung komplett zu verzichten und die neue ID selbst zu erzeugen.
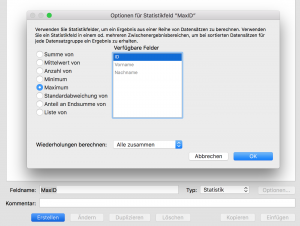 Das ist auch nicht schwer. Dafür erzeugen wir in der Tabelle ein neues Statistikfeld „MaxID“, das das Maximum unseres numerischen Schlüsselfelds ID trägt. Für die automatische Eingabe bei der Erzeugung eines neuen Datensatzes geben wir bei ID die einfache Formel „MaxID + 1“ ein.
Das ist auch nicht schwer. Dafür erzeugen wir in der Tabelle ein neues Statistikfeld „MaxID“, das das Maximum unseres numerischen Schlüsselfelds ID trägt. Für die automatische Eingabe bei der Erzeugung eines neuen Datensatzes geben wir bei ID die einfache Formel „MaxID + 1“ ein.
Wichtig ist hier noch, dass bei der Eingabe der Formel das Häkchen bei „Nicht berechnen, wenn verwendete Felder leer sind“, nicht gesetzt ist, damit wir auch bei leerer Tabelle einen gültigen Wert für die neue ID bekommen.
 Vom Benutzer erzeugte Lücken in der Folge der IDs bleiben erhalten und es gibt (zunächst) keine Kollisionen bei der Erzeugung neuer Datensätze.
Vom Benutzer erzeugte Lücken in der Folge der IDs bleiben erhalten und es gibt (zunächst) keine Kollisionen bei der Erzeugung neuer Datensätze.
Aber auch hier schlummert ein Problem. Das Statistikfeld „MaxID“ bezieht sich auf die aktuelle Ergebnismenge! Wenn wir also nicht alle Datensätze in der aktuellen Ergebnismenge haben (z.B. durch ein Suchen), kann es bei der Erzeugung von neuen Datensätzen wieder zu Kollisionen kommen. Wir müssen also sicherstellen, dass vor der Erzeugung von neuen Datensätzen alle Datensätze gefunden wurden (z.B. mit dem Scriptschritt „Alle Datensätze anzeigen“), aber das ist wieder hässlich und manchmal auch gar nicht möglich.
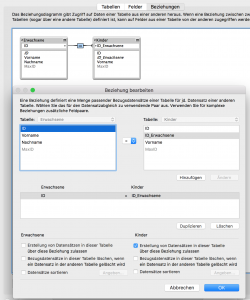
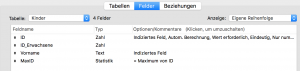 Schauen wir uns dazu folgendes Beispiel an: Wir haben eine Datenbank, in der Erwachsene und ihre Kinder gehalten werden sollen. Die Kinder sollen eine editierbare, eindeutige numerische ID bekommen und über ein Portal in der Tabelle der Erwachsenen erzeugt werden. Die Tabelle „Kinder“ hat wieder eine ID nach dem o.b. Mechanismus und ein Schlüsselfeld für die ID in der „Erwachsenen“-Tabelle. Eine Beziehung zwischen der „Erwachsenen“- und der „Kinder“-Tabelle erlaubt die Erzeugung von neuen Datensätzen bei den Kindern. Damit können über ein Portal im Layout der „Erwachsenen“-Tabelle neue Kinder angelegt werden.
Schauen wir uns dazu folgendes Beispiel an: Wir haben eine Datenbank, in der Erwachsene und ihre Kinder gehalten werden sollen. Die Kinder sollen eine editierbare, eindeutige numerische ID bekommen und über ein Portal in der Tabelle der Erwachsenen erzeugt werden. Die Tabelle „Kinder“ hat wieder eine ID nach dem o.b. Mechanismus und ein Schlüsselfeld für die ID in der „Erwachsenen“-Tabelle. Eine Beziehung zwischen der „Erwachsenen“- und der „Kinder“-Tabelle erlaubt die Erzeugung von neuen Datensätzen bei den Kindern. Damit können über ein Portal im Layout der „Erwachsenen“-Tabelle neue Kinder angelegt werden.
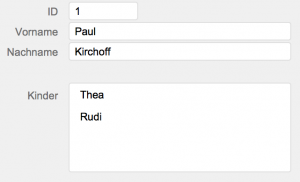
 Das funktioniert auch beim ersten Erwachsenen prima, aber schon beim zweiten Erwachsenen haben wir bei der Erzeugung neuer Kinder (datentechnisch) eine Kollision der Kinder-IDs erzeugt (mit einer etwas kryptischen FileMaker-Fehlermeldung). Das liegt daran, dass das Portal auf die Kinder-Tabelle eine implizite Suche nach Kindern dieses Erwachsenen ausführt und das Feld MaxID nicht mehr alle Kinder in der Kinder-Tabelle berücksichtigt.
Das funktioniert auch beim ersten Erwachsenen prima, aber schon beim zweiten Erwachsenen haben wir bei der Erzeugung neuer Kinder (datentechnisch) eine Kollision der Kinder-IDs erzeugt (mit einer etwas kryptischen FileMaker-Fehlermeldung). Das liegt daran, dass das Portal auf die Kinder-Tabelle eine implizite Suche nach Kindern dieses Erwachsenen ausführt und das Feld MaxID nicht mehr alle Kinder in der Kinder-Tabelle berücksichtigt.
 Das kann man auch nicht verhindern. Durch die Erzeugung neuer Kinder über das Portal wird die Suche in der Kinder-Tabelle automatisch durchgeführt; das Portal enthält nur die Teilmenge aller Kinder, die zu diesem Erwachsenen gehören.
Das kann man auch nicht verhindern. Durch die Erzeugung neuer Kinder über das Portal wird die Suche in der Kinder-Tabelle automatisch durchgeführt; das Portal enthält nur die Teilmenge aller Kinder, die zu diesem Erwachsenen gehören.
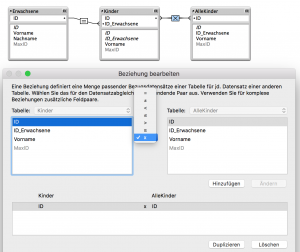 Hier hilft uns eine eher selten benutzte Beziehung in FileMaker weiter. Wir erzeugen im Beziehungsdiagramm ein neues Auftreten der Kinder-Tabelle und nennen es z.B. „AlleKinder“. Wir verknüpfen nun dieses Auftreten mit der ursprünglichen Kinder-Tabelle über ein beliebiges Feld (z.B. ID) mit dem „kartesisches Produkt“-Operator (X). Damit sind alle Datensätze der Kinder-Tabelle über eine beliebige Teilmenge der Kinder-Tabelle sichtbar.
Hier hilft uns eine eher selten benutzte Beziehung in FileMaker weiter. Wir erzeugen im Beziehungsdiagramm ein neues Auftreten der Kinder-Tabelle und nennen es z.B. „AlleKinder“. Wir verknüpfen nun dieses Auftreten mit der ursprünglichen Kinder-Tabelle über ein beliebiges Feld (z.B. ID) mit dem „kartesisches Produkt“-Operator (X). Damit sind alle Datensätze der Kinder-Tabelle über eine beliebige Teilmenge der Kinder-Tabelle sichtbar.
Nun müssen wir nur noch die Formel bei der ID-Generierung anpassen:
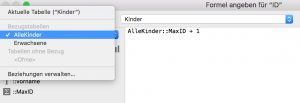 Statt die MaxID aus der aktuellen Sicht der Kinder-Tabelle zu verwenden, nutzen wir das aus dem „AlleKinder“-Auftreten; das wird auf jeden Fall aus der Ergebnismenge berechnet, die alle Kinder umfasst.
Statt die MaxID aus der aktuellen Sicht der Kinder-Tabelle zu verwenden, nutzen wir das aus dem „AlleKinder“-Auftreten; das wird auf jeden Fall aus der Ergebnismenge berechnet, die alle Kinder umfasst.
Und schon haben wir keine Kollisionen mehr bei der Erzeugung neuer Kinder über das Portal.
Hier ist die Beispiel-Datenbank, die die hier beschriebene Lösung implementiert.